
搜尋引擎如何運作?
搜尋引擎有三項主要功能:
- 抓取:搜尋網路上所有內容,查看所找到每個URL裡的程式碼及內容。
- 索引:在爬取過程中所蒐集到的網頁資料,會儲存和組織起來。一旦網頁進入索引,就會開始運行並顯示相關搜尋結果。
- 排名:提供最符合搜尋者查詢的內容,這表示顯示的結果排序方式會從最相關到最不相關。
搜尋引擎在抓取什麼內容?
搜尋引擎派遣搜尋機器人(通常稱為搜尋器或搜尋蜘蛛),去尋找與更新網站內容,這個過程就是抓取。抓取的內容很廣泛,可以是網頁、圖片、影片、PDF等,但是不管何種形式,內容都是以連結形式被搜尋蜘蛛找到。
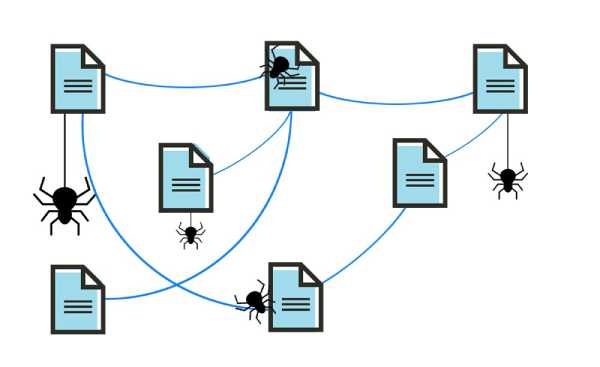
Googlebot首先會取得一些網頁,再跟隨這些網頁上的連結找到新的URL。沿著連結的路徑,搜尋蜘蛛可以找到新的內容並把它們加入到咖啡因索引架構──這是一個Google的大數據庫,用來儲存已發現的URL。往後搜尋者可以在這些URL上找到想要的資訊內容。
哪些資訊會讓搜尋引擎放入索引?
搜尋引擎處理並儲存它們找到的訊息,再建立起龐大的數據庫,這涵蓋搜尋引擎認為能供提搜尋者使用的所有內容。
搜尋引擎排名
當有人進行搜尋時,搜尋引擎會在索引中搜尋高度相關的內容,然後對這些內容進行排序,以期解決搜尋者的查詢。這種把搜尋結果按相關性的順序排序稱為排名。通常來說,可以假設網站的排名越高,搜尋引擎認為該網站與搜尋者的查詢問題越相關。
有時你會想避免搜尋引擎索引你的某個網頁或是整個網站,又或許你想指示搜尋引擎將不要將某些網頁儲存到索引裡,儘管這樣做一定有某些原因,但如果你希望網站可以被使用者找到,還是要確保搜尋蜘蛛可以訪問你的網站並編入索引,不然你的網站會如同隱形一般。
在這章節的最後,會教你如何讓網站內容與搜尋引擎共同配合工作,而不是與搜尋引擎相互牴觸。
抓取:搜尋引擎可以找到你的網頁嗎?
正如剛剛所了解,以能在搜尋結果頁面【SERP】顯示為主要前提,確認你的網站可以被抓取到以及放進索引。如果你已經有網站,最好先在索引裡面查自己的網站有多少網頁被收錄,然後再開始。這會讓你對你的網站有些想法,例如你想要Google對你的網頁如何抓取及尋找、還有不希望被找到的內容。
"site:yourdomain.com"是一個可以檢查你被收入檢索的網頁的方式,這是一個更進階的搜尋運算機器。前往Google,然後在搜尋欄中輸入“site:yourdomain.com” ( Google搜尋運算符號 )。
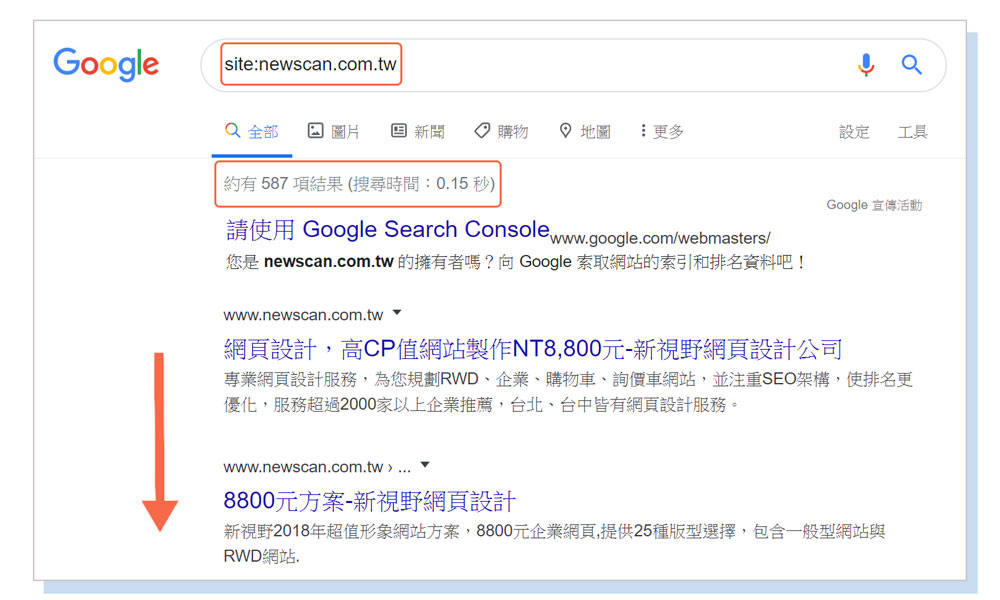
Google所顯示的結果數量(關於XX個結果)並不確切,但是它確實讓你了解資料庫裡已經收錄了你的網站裡哪些網頁,以及這些網頁在目前搜尋結果中的情況。
為了獲得更準確的結果,請在Google Search Console中監控和使用“索引覆蓋率”報告,如果你現在沒有Google Search Console帳戶,你可以免費的註冊一個,有了這個工具,你可以為你的網站提交網站地圖,還能監控實際Google索引了多少提交的網頁。
如果你的網站沒有在搜尋結果中顯示,有幾個可能性:
- 你的網站剛建好,搜尋蜘蛛尚未抓取到你的網頁資料。
- 沒有外部連結可以連結到你的網站。
- 你的網站架構或是導航選單,難以被搜尋蜘蛛有效地抓取資料。
- 你的網站含有會阻擋搜尋引擎的程式碼。
- 你的網站因為濫用垃圾郵件,而被Google處罰。
大部分的人都想著要確保Google可以找到他們網站的重要網頁,但也有些網頁並不想讓Google找到。其中有可能包含內容薄弱的舊網址、重複的網址(例如電子商務的排序和過濾器參數)、特殊的促銷代碼頁、登入網頁或測試頁等。
如果要讓Googlebot忽略網站的某些網頁資料,你可以使用robots.txt。
Robots.txt
Robots.txt文件位於網站的根目錄中,這份文件會建議搜尋引擎要抓取網站的是哪些部分,與他們抓取您網站的速度,特定Robots指令集 ( specific robots.txt directives )。
Googlebot如何處理robots.txt文件
- 如果Googlebot在你的網站沒有找到robot.txt,它會繼續爬取網站。
- 如果Googlebot在你的網站發現robot.txt,通常它會遵守建議並繼續爬取網站。
- 如果Googlebot在嘗試訪問網站裡robot.txt文件時遇到錯誤,而且無法判斷該網站是否存在,Googlebot就不會爬取網站。
並非所有網路機器人都遵循robot.txt的建議。不懷好心的人會構建不遵循robot.txt協議的機器人 (例如:使用電子郵件地址抓取工具),實際上,有些心懷不軌的人會使用robots.txt文件來尋找你的私人內容所在位置。
阻止爬網程序運作在像是登錄和管理網頁之類的,讓私人網頁不會顯示在索引中,這看起來是很合理的作法。但是將這些URL的位置放在可公開訪問的robots.txt文件中,也意味著有心人士可以輕鬆地找到這些私人內容。所以最好使用NoIndext處理這些網頁,並將它們放在登錄表單後面,而不是將其放在robots.txt文件中。
在GSC(Google Search Console)中定義URL參數
透過將某些參數加到URL,某些網站(常見為電子商務網站)就可以在許多個不同的URL上提供相同的內容。如果你曾經網購過,你可能會透過過濾器縮小尋找範圍。例如:你在Amazon搜尋「鞋子」,然後按大小、顏色和樣式優化搜尋。每次優化時,URL都會略有變化。
Google可以在找出主要網址部份做得很好,知道要提供給搜尋者哪種URL,但是你也可以使用Google Search Console中的「URL參數」功能來確切告訴Google你希望它們如何處理你的網頁。如果你用GSC告訴Googlebot「不要使用____參數抓取URL」,那實際上是在要求Googlebot隱藏此內容,可能會導致這些網頁從搜尋結果中刪除,如果這些參數造成重複網頁,這些網頁也不太可能被收錄進索引。
可以讓搜尋蜘蛛找到您的網站裡所有重要內容嗎?
有時搜尋引擎有辦法透過抓取尋找你的網站裡部分內容,但是其它網頁或部分網頁可能由於某種原因而被阻擋,最重要的就是,確保搜尋引擎能夠發現所有你想要被收錄進檢索的內容,而不只是首頁而已。
所以你可以問問看自己:搜尋蜘蛛是否能徹底抓取你整個網站,而不只是造訪而已?

您的內容是否隱藏在登錄表單後面?
如果您要求用戶在訪問某些內容之前必須先登錄,填寫表格或回答調查,搜尋引擎將無法看到那些受保護的頁面,搜尋蜘蛛絕對不會試圖登錄網站。
您是否很依賴搜尋欄位?
有些人相信如果他們在網站安置一個搜尋欄位,搜尋引擎將能夠為訪客找到所有事物,但是搜尋蜘蛛是透過連結抓取資料,無法使用搜尋欄位找到資訊。
文字是否隱藏在非文字的內容裡?
希望被索引的文字,不應該放在無法被解讀的媒體形式裡(例如圖像、影片、GIF等)裡,雖然搜尋引擎越來越懂得辨認圖像,但不能保證他們能閱讀和理解圖像含意,最好還是在網站內使用<HTML>標示文字內容。
搜尋引擎可以追踪您的網站導航嗎?
就像搜尋蜘蛛需要通過其他網站的連結來發現你的網站一樣,在一個網站裡面,它也需要連結路徑,藉由您自己網站上的連結路徑來引導每個網頁之間的連結。但是,如果你有一個網頁,希望搜尋引擎可以找到它,卻沒有從任何其他網頁連結到這個網頁,那麼搜尋引擎就無法找到它。
許多網站都犯了嚴重的錯誤,就是用了搜尋引擎無法訪問的方式來架構網站導航選單,阻礙了網站被索引與加入搜尋結果頁面。
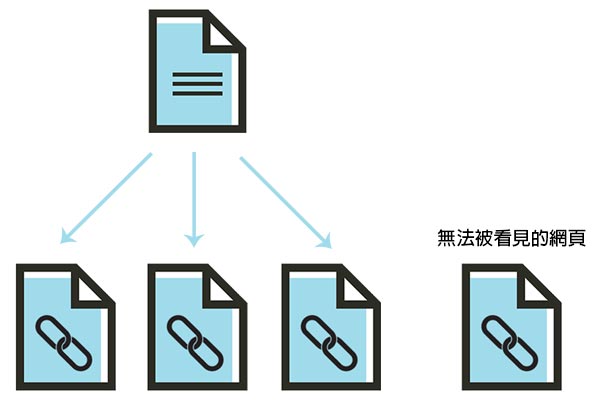
常見的網站導航錯誤可能使搜尋蜘蛛無法看到您的所有網頁:
- 行動版網站導航連結與桌上電腦網站導航連結不同。
- 不使用HTML中的任何類型連結網站導航,例如啟用JavaScript的網站導航,目前Google在抓取和理解Javascript方面已經進步很多,但還是不夠完美,將資訊放入HTML中,更加確保Google能找到、理解這些資訊,並且將它們收錄索引。
- 為特定類型的訪問者顯示獨有的網站導航,或是其他個性化的導航方式,可能會被搜尋引擎的機器人隱藏。
- 忘記透過網站導航連結到你的網站首頁,要記得,連結是搜尋蜘蛛進入新網頁的路徑!
以上就是網站為何必須要有清楚的網站導航,以及良好的文件夾結構式URL,最重要的原因。
您的網站有清楚的資訊架構嗎?
資訊架構是一種訊息結構和內容標記,優秀的資訊架構可以提供更便捷與快速的網站給使用者使用。
最好的資訊架構是很直覺的,這代表使用者可以不費力的瀏覽網站與查詢內容。
您是否有使用SiteMap?
sitemap就如它的字面涵義:告訴搜尋蜘蛛如何找到你的網站資料,並將資料收錄索引。而確保Google查找優先級最高的網頁的最簡單方法,是創建符合Google標準的文件,然後通過Google Search Console提交文件。雖然提交sitemap並不能代替良好的網站導航,但能肯定的是,這可以幫助搜尋蜘蛛通往所有重要網頁的路徑。
如果沒有其它網頁連結到你的網站,可以透過在Google Search Console中提交sitemap.xml來對你的網站進行索引。雖然不能保證他們能將在索引中完整收錄你提交的URL,但是值得一試!
搜尋蜘蛛嘗試訪問您的URL時是否出錯?
在搜尋你的網站上的URL的過程中,搜尋蜘蛛可能會遇到錯誤。你可以向Google Search Console的「抓取錯誤」報告,以檢測此網址可能發生什麼錯誤─該報告會向你顯示伺服器錯誤和未找到的錯誤。
伺服器日誌文件還可以向你顯示伺服器錯誤和未找到的錯誤信息,以及其他信息(例如抓取頻率),但這是一種更高端的策略,因此我們不會在初學者指南中詳細討論它。
你必須先了解伺服器錯誤和「未找到」錯誤,然後才能對抓取錯誤報告進行有意義的操作。
4xx代碼:當搜尋蜘蛛因為用戶端錯誤而無法訪問您的網站內容時
4xx錯誤是用戶端錯誤,這表示請求的URL語法錯誤或無法實現。
最常見的4xx錯誤是「404 ─ 未找到」錯誤,這可能是因為URL打錯、網頁已刪除或重定向錯誤...等因素所造成的。當搜尋引擎搜尋到404時,它們會無法訪問該URL,當用戶點擊到遇到404的網頁時,他們可能會感到沮喪而離開。
5xx代碼:當搜尋蜘蛛由於伺服器錯誤而無法訪問您的網站內容時
5xx錯誤是伺服器錯誤,這表示網頁所在的伺服器無法滿足搜尋者或搜尋引擎訪問該網頁的請求,在Google Search Console的“抓取錯誤”報告中,有一個專門針對這些錯誤的標籤。
這些通常是由於對URL的請求已過時而造成,因此Googlebot放棄了該請求。 查看Google’s documentation,以了解更多解決伺服器連接問題的相關資訊,值得慶幸的是,有一種方法可以告知搜尋者和搜尋引擎你的網頁已移動──使用301(永久)重定向。

搜尋引擎需要一個可以連結舊網址與新網址的橋樑,這個橋梁就是301重定向。
當你實施301重定向時:
- 連結權重:將連結權重分數從舊位置轉移到新URL。
- 索引編制:幫助Google查找新版本的頁面,並為其建立索引。
- 使用者體驗:確保使用者可以找到他們想找到的頁面。
如果你沒有實施301重定向:
- 連結權重:先前URL的權重不會傳遞到新版本的URL。
- 索引編制:僅在你的網站上出現404錯誤並不會損害搜索性能,但被投放的404頁面可能會不被收錄索引,損害往後網站的訪問量與排名。
- 使用者體驗:允許訪問者點擊無效連結會把他們帶到錯誤頁面,而不是預期的頁面,這可能會令使用者感到沮喪。
301狀態表示該網頁已永久移到新位置,因此請避免將URL重定向到不相關的網頁,也就是舊URL的內容與新URL的內容是不同的,如果網頁正在優化查詢排名,而網頁使用301轉址到不同內容的URL,則該網頁的排名可能會下降,因為這個網頁與特定查詢的相關內容已經不存在,301轉址的功能是很強大的,所以要更小心使用301轉址!
你也可以選擇302轉址,但這是在網站暫時轉址,是在不太需要傳遞URL權重情況下使用,302轉址有點像繞道而行,讓你的網站暫時通過某條路徑吸引流量,但不會永遠保持這種情況,在確定你的網站針對搜尋蜘蛛部份進行了優化之後,下一個步驟就是要確保你的網站可以被索引。
索引:搜尋引擎如何解釋和儲存您的網頁?
你的網站可以被搜尋引擎發現及抓取,但這並不表示它可以被儲存在索引內,先前在文章抓取部分,討論搜尋引擎如何發現你的網頁,索引是這些被搜尋引擎發現的網頁所存放的位置,在搜尋蜘蛛找到網頁之後,搜尋引擎就會像瀏覽器一樣顯示網頁,顯示網頁的過程,搜尋引擎要分析網頁內容,所有的資訊也因此被儲存至索引。

繼續閱讀來了解索引功能是如何運作,以及怎麼確保你的網站內所有重要資料被收錄索引。
我有辦法知道Googlebot搜尋器如何看到我的網頁嗎?
可以,網頁的緩存版本會顯示Googlebot上次抓取網站的頁庫存檔(snapshot)。
Google會以不同的頻率抓取和緩存網頁,與知名度較低的網站相比,較常發文的知名大網站,會被搜尋蜘蛛更頻繁地爬取網頁內容。
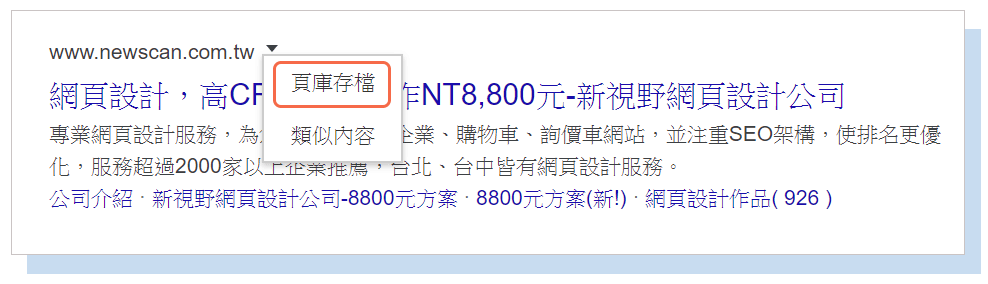
你可以在搜尋結果網頁上,點取網址旁的下拉選單,就能看到你的網頁的頁庫存檔。這個方式還可以讓你去看網站的純文字版或原始碼,以確定重要內容是否被有效地爬取和緩存。
網頁是否曾經從索引中刪除?
是的,網頁會從索引中刪除!造成這個結果主要原因包括:
- URL處於「找不到」錯誤(4XX)或服務器錯誤(5XX)─ 這可能因為網頁已經移動卻尚未設置301重定向,或網頁被刪除並進行了404處理,因此將此網頁從索引中刪除。
- URL中添加了「noindex」meta標記 ─ 網站所有者可以添加此標記,指示搜尋引擎在索引中省略該網頁。
- 因為違反了搜尋引擎的《站長指南》,該網址被懲罰,因此已從索引中刪除。
- 這個URL阻止搜尋蜘蛛爬取,例如:添加了需要密碼才可以進入該網頁的限制。
如果你認為應該已經存在索引中的網頁,卻沒有繼續在Google顯示,可以使用【網址檢查工具】來了解此網頁的狀態。
告訴搜尋引擎如何為您的網站建立索引
Meta指令
meta指令(或「meta tags」)是你可以向搜尋引擎提供如何處理網頁的相關說明。
你可以對搜尋蜘蛛下指令,例如「不要在搜尋結果中將此網頁編入索引」或「不要將某頁的連結權重傳遞給另一網頁」,這些指令是通過HTML網頁中的Robots Meta標籤(最常用)或HTTP標頭中的X-Robots-Tag執行的。
Robots Meta標籤
可以在網頁HTML的中使用Robots Meta標籤,它可以排除所有或特定的搜尋引擎。
以下是最常見的Robots Meta標籤,以及使用方式。
index / noindex:告訴搜尋引擎是否要爬取這個網頁,並保留在索引內,以便日後進行檢索,如果你選擇使用"noindex",則告訴搜尋蜘蛛不要把這個網頁編入索引,在預設情況下,搜尋引擎會將找到的所有網頁編入索引,所以不太會需要用到"index"標籤。
•何時使用:如果你嘗試從Google網站索引中刪除一些不想被索引的內容單薄網頁(例如:用戶生成的個人資料頁),但仍希望網頁能被訪問,則可以將網頁標記為"noindex"。
follow / nofollow:告訴搜尋引擎網頁上的要不要追蹤這個連結,"follow"會讓搜尋蜘蛛追蹤你的網頁上的連結,並將連結權重傳遞給這些URL,或者,如果選擇使用"nofollow",則搜尋引擎將不會跟踪此連結,或將任何連結權重傳遞給新連結,通常預設所有網頁都具有"follow"屬性。
‧何時使用:你想阻止網頁被索引以及阻止搜尋蜘蛛追踪網頁上的連結時,通常"nofollow"與""noindex"會一起使用。
noarchive:用來限制搜尋引擎保存網頁的緩存副本。在預設情況下,引擎將保持已索引的所有網頁的可見副本,搜尋者可以通過搜尋結果中的緩存連結來訪問網頁緩存副本。
•何時使用:如果你是經營電子商務網站,價格會定期變化,則可以考慮使用noarchive標籤,以防止搜尋者看到過時的價格。
X-Robots 標籤
X-Robots-Tag用於HTTP標頭中,它比meta標籤具有更多的靈活性和功能,想阻止搜尋引擎爬取某些大規模的網站內容,X-Robots-Tag也可以使用正規表達式,在網站內使用noindex標籤,阻止非HTML文件被爬取到。
例如,你可以輕鬆排除整個文件夾或文件類型(like moz.com/no-bake/old-recipes-to-noindex):
或特定的文件類型(如PDF):
有關Meta Robot標籤的詳細信息,請瀏覽Google的Meta Tag規範
了解影響抓取和索引的不同方法,能幫助你避免遇到無法找到重要網頁的常見陷阱。
排名:搜尋引擎如何對URL進行排名?
為了確定搜尋結果的相關性,搜尋引擎使用演算法或公式,儲存能以有意義的方式來檢索和排序的訊息,這些年來,這些算法經歷了許多變化,以提高搜尋結果的質量,Google每天都會進行調整演算法內容,同時也為特定問題進行算法更新,像是企鵝演算法就用於解決垃圾郵件問題。
.jpg)
為什麼算法如此頻繁地更改? Google只是想讓我們保持警惕嗎?
儘管Google不透露他們要做什麼的細節,但我們知道Google調整演算法的目的是提高整體搜尋質量,如果你的網站在演算法調整後遭受了損失,請將其與【Google’s 品質指南】 或【Search Quality Rater Guidelines】進行比較,兩者都可以仔細說明了搜尋引擎的需求。
搜尋引擎想要的是什麼?
搜尋引擎一直希望以最好的方式為搜尋問題的人提供最有用的解答,如果真是這樣,那為什麼現在的SEO與之前不同呢?
從學習新語言的角度思考。
隨著時間的推移,學習語言的學生會越來越了解語言,並且能分辨出語言背後的含義以及單詞和片語之間的關係,最後,透過足夠的練習,他們就會非常了解該語言,甚至可以理解細微差別,並且能夠為模糊或不完整的問題提供答案。
當搜尋引擎剛剛開始學習我們的語言時,要使用違反品質準則的技巧與策略來對系統進行欺騙是較容易的,以關鍵字填充為例,如果你使用「有趣的笑話」之類的特定關鍵字進行排名優化,則可以在頁面上多次添加「有趣的笑話」一詞,並將其加粗體,以期提高該它的排名:
歡迎加入有趣的笑話!我們講世界上最有趣的笑話。有趣的笑話既有趣又瘋狂。你有趣的笑話在等待。坐下來閱讀有趣的笑話,因為有趣的笑話可以使你開心和有趣,一些有趣的喜歡的有趣笑話。
一段文字裡,不斷以同樣的文字轟炸搜尋者,不但難以閱讀甚至很惱人。這種搜尋經驗造成可怕的用戶體驗,這類的關鍵字填充策略在過去曾經可以奏效,但這不是搜尋引擎想要提供的搜尋結果。
連結在SEO中扮演的角色
連結有兩種,一種是反向連結,又稱「入站連結」,反向連結意思是從其他網網站指向你的網站的連結,另一種是內部連結,意思是指在自己的網站內指向其他網頁,但是都在同一個網站內。
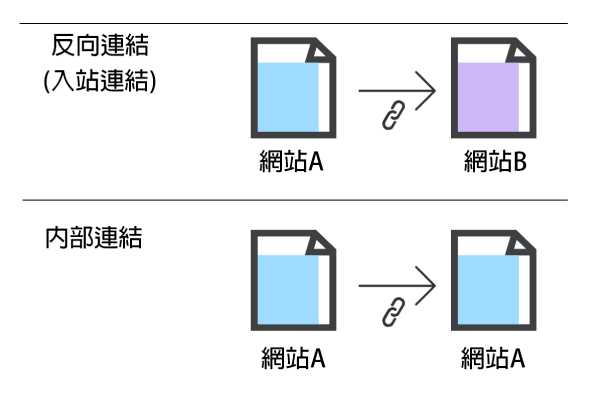
連結在SEO中一直扮演著重要角色。早期,搜尋引擎需要幫助來確定哪些URL比其他URL更值得信賴,以幫助它們對搜尋結果進行排名。透過計算到特定網站的連結數量,可以幫助搜尋引擎排名。
反向連結與口碑介紹非常相似。假設一間「珍妮咖啡店」為例:
•他人推薦 = 提升網站權重的好機會
o範例:許多人都告訴過你,珍妮咖啡店是這附近最好的咖啡
•你自己推薦 = 有偏見,不是提升網站權重的好辦法
o範例:珍妮聲稱她的咖啡是這附近最好的
•來自不相關或低品質的推薦 = 並非是提升網站權重的好跡象,甚至可能使你的網站郵件被標記為垃圾郵件
o範例:珍妮付錢讓從未去過她的咖啡店的人告訴其他人她的咖啡有多好。
•無推薦 = 無法確定網站權重
o範例:珍妮的咖啡可能不錯,但是找不到任何有推薦的人,因此無法確定。
這就是創建PageRank的原因。PageRank(Google核心演算法的一部分)是一種連結分析算法,以Google的創始人之一拉里·佩奇(Larry Page)命名。
PageRank透過測量指向網頁的連結的質量和數量來估計網頁的重要性,假定網頁越相關、越重要和值得信賴,網頁會獲得越多連結。
如果是從高權重(受信任)網站獲得的自然反向連結越多,你的網站在搜尋結果中的排名就越高的機率就越大。
內容在SEO中所扮演的角色
如果連結沒有將搜尋者導引某個"地方",那就沒有意義了,那個"地方"就是"內容"!
每當有人執行搜尋時,就會有成千上萬種可能的結果,那麼搜尋引擎如何確定搜尋者最後會找到它所需要的網頁呢? 搜尋結果頁面呈現排名位置時給查詢者時,內容與查詢意圖的匹配程度是很重要的的。 換句話說,此頁面與搜尋到的字詞是否匹配,並且是否有幫助到搜尋者完成他的的任務?
由於專注於用戶滿意度和任務完成上,因此對於文章內容應該多長,應該包含多少關鍵字,標題與標記需要多少關鍵字,是沒有嚴格的標準的, 所以有這些因素都可以影響頁面在搜尋的效果,但是重點應該放在將要閱讀內容的使用者上。
什麼是RankBrain?
RankBrain是Google核心演算法的學習機器組件,學習機器是一種電腦程序,可以透過新的觀察結果和修正數據,不斷改進其預測,換句話說,它一直在學習,所以搜尋結果品質會不斷提高。
例如,如果RankBrain注意到排名較低的網址,為用戶提供的內容比排名較高的網址好,則RankBrain會調整這些結果,將相關性更高的結果移到更高的位置,並將相關性較低的網頁降級。
RankBrain對SEO的意義是?
由於google將繼續利用rankbrain來推廣最相關、最有用的內容,因此我們需要比以前更專注在滿足搜尋者的意圖,為了讓用戶能在你的網頁裡找到最佳訊息而有最佳的使用者經驗,您的網站就必須在rankbrain中表現良好。
參與度指標:相關性、因果關係,或兩者兼具?
在google排名中,參與度指標很可能與相關性是因果關係。
當我們說參與度指標時,是指代表搜尋者如何通過搜尋結果與你的網站進行交換的數據。這包括以下內容:
- 點擊:通過搜尋訪問。
- 網頁停留時間:訪客離開前,在網頁上停留的時間。
- 跳出率:用戶僅瀏覽一頁,與瀏覽超過一頁的百分比。
- Pogo-sticking:在自然搜尋結果的網頁中,單擊其中一個網站,然後快速返回到搜尋結果網頁再點擊另一個網站。
包括Moz自己調查的排名因素在內,許多測試都表明──參與度指標與更高的排名相關,但因果關係一直爭議不斷。究竟是好的參與度指標只是表明排名較高的網站?還是因為網站有好的參與度指標而使其排名很高?在google排名中,參與度指標很可能與相關性是因果關係。
Google怎麼說?
儘管他們從未使用過「直接排名信號」一詞,但Google明確表示,他們絕對會使用點擊數據來修改特定查詢的搜尋結果頁面【SERP】。
根據Google前搜尋質量總監Udi Manber的說法:
「排名本身受到點擊數據的影響,我們發現,對於特定查詢,80%的用戶單擊第二名網站,而只有10%的用戶單擊排名第一的網站,過一會兒,就會發現排名第二名的網站是人們想要的,我們就會調整網站排名。」
由於Google需要維持和改善搜尋質量,參與度指標不僅只是相關而已,但是Google並沒有將參與度指標稱為「排名信號」,因為這些指標用於改善搜尋品質,而網站排名只是衍生出來的副產品。
哪些測試已確認?
各種測試已證實google會根據搜尋者的參與度來調整搜尋結果頁面【SERP】順序:
- 蘭德·菲甚金(Rand Fishkin)在2014年的測試:大約200人點擊了搜尋結果頁面【SERP】上的網址,結果排名從第七上升到第一,有趣的是,排名改善似乎與訪問該連結的人的位置無關,在許多參與者所在的美國,網站排名飆升,而在加拿大,澳大利亞等Google網頁上,排名卻一直較低。
- 拉里·金(Larry Kim)比較:RankBrain對於首頁平均停留時間的比較測試,Google演算法降低了停留時間較短的網頁的排名。
- Darren Shaw的測試:表明用戶行為也會對本地搜尋和地圖結果產生影響。
由於用戶參與度指標用於調整搜尋結果頁面【SERP】的品質,並進行排名,因此可以肯定地說SEO應該針對參與度進行優化,因此,如果你的網頁或其反向連結沒有變化,但搜尋者的行為表明他們更喜歡其它網頁,則排名可能會下降。
在對網頁進行排名方面而言,參與度指標是用於檢查實際狀況的作用,像是連結和內容之類的客觀因素首先會在網頁上排名,如果在網頁排名方面有誤,參與度指標就可以幫助Google進行調整。
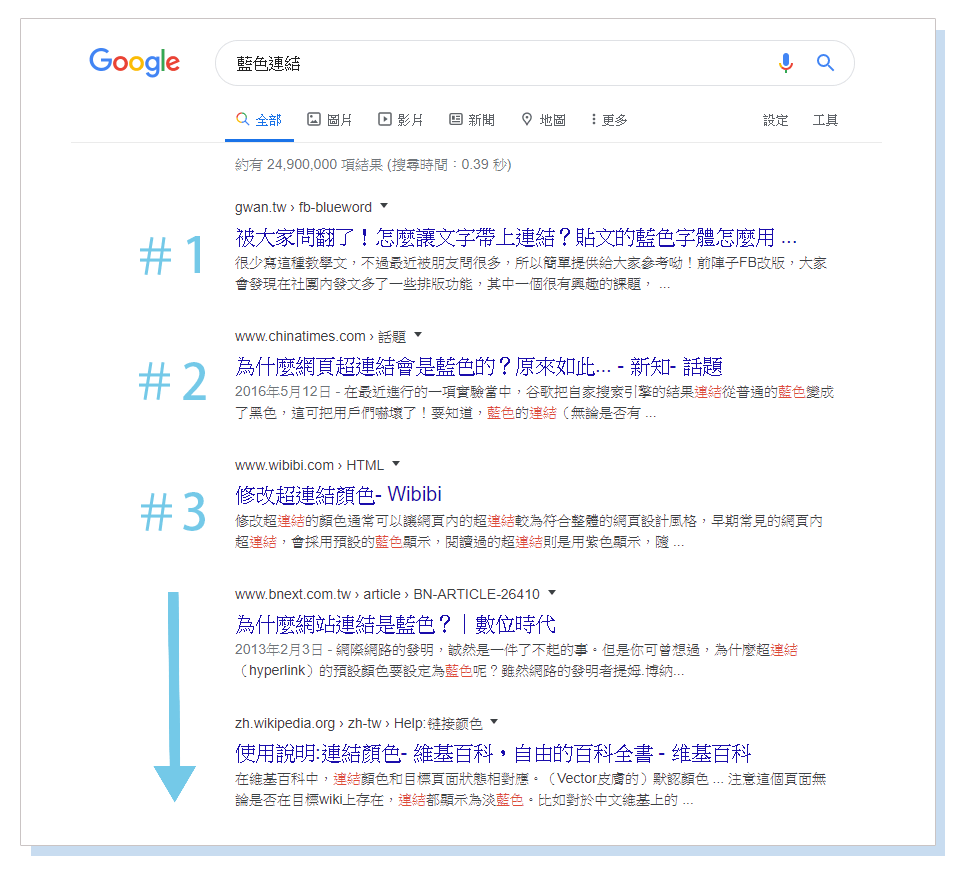
搜尋結果的演變
在以前搜尋引擎不像今天那麼複雜的時候,當初人們稱為,術語「10個藍色連結」的扁平結構為搜尋結果頁面【SERP】。每次執行搜尋時,Google都會呈現一個包含10個自然結果的網頁,每個結果都採用相同的格式。
在這個搜尋環境中,可以排名第一代表了取得SEO的聖杯,但是後來發生了一些事情,Google開始在搜尋結果網頁上添加新格式的結果頁面,稱為SERP功能。這些SERP功能包括:
- 付費廣告
- 精選短文
- 問答集
- 本地(地圖)包
- 知識面板
- 網站連結
Google一直在增加新的功能。他們甚至進行了「零結果搜尋結果頁面【SERP】」實驗,該現像是SERP上僅顯示了知識圖的一個結果,除了「查看更多結果」的選項外,再也沒有顯示其他的結果。
這些添加的功能造成初期的一些恐慌,主要原因有兩個,第一,許多功能導致自然搜尋結果在搜尋結果頁面【SERP】上更往下降。第二是,由於在搜尋結果頁面【SERP】本身上回答了更多查詢,因此點擊了搜尋結果頁面【SERP】的搜尋者更少了。
那麼,為什麼Google會這樣做?這一切都可以追溯到搜尋體驗,用戶行為表明,不同的內容格式可以更好地滿足某些查詢,要注意,不同類型的搜尋結果頁面【SERP】功能是如何與不同類型的查詢意圖匹配。
|
搜尋意圖 |
可能觸發的搜尋結果頁面【SERP】功能 |
|
訊息 |
精選短文 |
|
一個答案的信息 |
知識圖/即時答案 |
|
本地的 |
地圖 |
|
交易性 |
購物 |
重要的是要知道答案可以多種格式傳遞給搜尋者,並且內容的結構會影響其在搜尋中的顯示格式。
本地化搜尋
Google擁有自己當地商家資訊的檢索,所以可以直接顯示本地搜尋結果。
如果你是有實體店面或是到府服務,要優化本地的SEO的話,必須確認你有在 Google My Business Listing 提交登記請求、驗證以及優化。
關於本地化搜尋,Google主要有前三個因素來決定網站排名:
1. 相關性
相關性是指當地的店家與搜尋者尋找符合性有多高,所以要確保商家資訊夠完整以及盡量符合搜尋者需求。
2. 距離
Google使用你的地理位置來提供更好的本地搜尋結果,本地搜尋對於鄰近度是很敏銳的,鄰近度指的是與搜尋者的位置,或查詢的指定位置。
3. 突出性
有突出性作為因素,Google希望獎勵現實世界中知名企業,除了企業影響力外,Google還希望可以再利用一些其他因素來確定本地排名。
(1.)評論
本地商家收到的Google評論數量,及其中的情緒,在網站排名上有明顯的影響力。
(2.)自然排名
SEO最佳做法也適用於本地SEO,因為Google在確定本地排名時還會考慮網站在自然搜尋結果中的位置。
(3.)平台網頁
「企業平台」或「企業列表」,在Web的本地化平台(Yelp, Acxiom, YP, Infogroup, Localeze,等) 上收錄了本地企業的名稱、地址、電話號碼(NAP)。
本地排名受本地的企業平台網頁引用數量和一致性的影響。Google會從各種各樣的來源中獲取數據,以不斷完善對本地業務索引。當Google找到許多個對公司名稱、位置和電話號碼的一致引用時,它會增強Google對數據有效性的「信任」。這能夠使Google更有信心展示本地業務。Google還會使用網絡上其他來源的信息,例如連結和文章。
4. 本地參與
Google不斷整合現實世界的數據,例如熱門的訪問時間和平均訪問時間。
為了持續豐富本地搜尋結果,還為搜尋者提供解決商務問題的能力!

而本地結果正受到現實數據的影響,這種是搜尋者與本地企業互動做出的反應,而不是純粹的靜態訊息(例如連結和平台網頁)。
由於Google希望向搜尋者提供最佳、最相關的本地業務,現實性互動指標來確定質量和相關性對搜尋者來說是非常有意義的。
歡迎推廣本文,請務必連結(LINK)本文出處:轉角SEO公司